redis的两种链接方式
简单链接
1 | import redis |
连接池
如果要链接redis的时候推荐用连接池的方式;如果每次操作都用同一个链接,可以使用连接池
redis使用connection_poll来管理对一个redis服务的所有链接,避免每次建立,释放链接的开销
默认每个redis实例都会维护一个自己的链接池。可以直接建立一个连接池,然后作为参数redis,这样
就可以实现多个redis实例共享一个连接池
1 | #连接池 |
例子
pool.py
1 | import redis |
view.py
1 | from django.shortcuts import render,HttpResponse |
Django-redis组件
安装: pip install django-redis
配置文件
1 | CACHES = { |
使用
1 | #利用django-redis组件进行连接 |
redis的字符串操作(string)
Sting操作,redis中的String在内存中按照一个name对应一个value来存储

1、set(name, value, ex=None, px=None, nx=False, xx=False) # 设置值
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
2、setnx(name, value)
设置值,只有name不存在时,执行设置操作(添加) #相当于只是添加,不能进行修改操作
3、setex(name, value, time)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
4、psetex(name, time_ms, value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
5、mset(*args, **kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mset({'k1': 'v1', 'k2': 'v2'})
6、get(name) 获取值
7、mget(keys, *args)
批量获取
如:
mget('ylr', 'zzz')
或
r.mget(['ylr', 'zzz'])
8、getset(name, value) 设置新值并获取原来的值
9、getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
# 如: "拉销量" ,0-3表示 "拉"
待续。。
redis的列表操作(list)
redis的散列表操作(类似于字典里面嵌套字典)
Hash操作,也叫做散列表操作。redis中Hash在内存中的存储格式如下
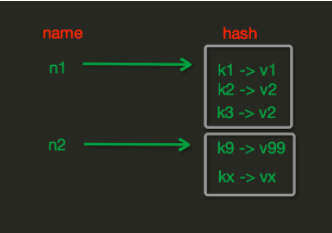
1、hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
2、hmset(name, mapping)
# 在name对应的hash中批量设置键值对
# 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
3、hget(name,key)
# 在name对应的hash中获取根据key获取value
4、hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
5、hgetall(name) 获取name对应的hash中的所有键值
6、hlen(name) 获取name对应的hash中键值对的个数
7、hkeys(name) 获取name对应的hash中所有的key的值
8、hvals(name) 获取name对应的hash中所有的value的值
9、hexists(name, key) 检查name对应的hash是否存在当前传入的key
10、hdel(name,*keys) 将name对应的hash中指定key的键值对删除
11、hincrby(name, key, amount=1) 吧原来的值自加1
hincrby ('xxx','slex',amount=-1) #吧原来的值自减1
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
12、hincrbyfloat(name, key, amount=1.0) 支持浮点型的
13、hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
14、hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# for item in r.hscan_iter('xx'):
# print item
# for item in r.hscan_iter('xx',match='*lx'): #匹配以lx结尾的
# print item

